Data Science in Drilling - Episode 8
- Zeyu Yan

- Jun 7, 2022
- 6 min read
Different Ways of Combining DataFrames in Pandas
written by Zeyu Yan, Ph.D., Head of Data Science from Nvicta AI
Data Science in Drilling is a multi-episode series written by the technical team members in Nvicta AI. Nvicta AI is a startup company who helps drilling service companies increase their value offering by providing them with advanced AI and automation technologies and services. The goal of this Data Science in Drilling series is to provide both data engineers and drilling engineers an insight of the state-of-art techniques combining both drilling engineering and data science.
Still a Pandas episode. Enjoy!

Enjoying great knowledge is just like enjoying delicious tomahawk steak.
Introduction
Joining tables is an important topic in SQL. When it comes to Pandas, it is also essential to master different ways of combining DataFrames. This article covers all one needs to know about this topic.
What We'll Cover Today
Combining DataFrames using pd.merge method.
Combining Series or DataFrames using pd.concat method.
Combining DataFrames Using pd.merge
The pd.merge method is a very important method for combining Pandas DataFrames. Recall that there are different ways of joining tables in SQL. The same can be realized for Pandas DataFrames using pd.merge method. To demonstrate how to use this method, let's first define two dummy DataFrames for testing:
import pandas as pd
import numpy as np
df_1 = pd.DataFrame({
'key': ['a', 'b', 'c', 'a', 'c'],
'val_1': np.random.randint(10, size=5)
})
df_2 = pd.DataFrame({
'key': ['b', 'c', 'e', 'c', 'f', 'a'],
'val_2': np.random.randint(10, size=6)
})
print(df_1)
print()
print(df_2)The two dummy DataFrames are:
key val_1
0 a 2
1 b 9
2 c 2
3 a 4
4 c 6
key val_2
0 b 1
1 c 5
2 e 2
3 c 7
4 f 5
5 a 2Let's first try to perform an inner join of the two DataFrames on the "key" column:
pd.merge(df_1, df_2, how='inner', on='key')The resulted DataFrame is:
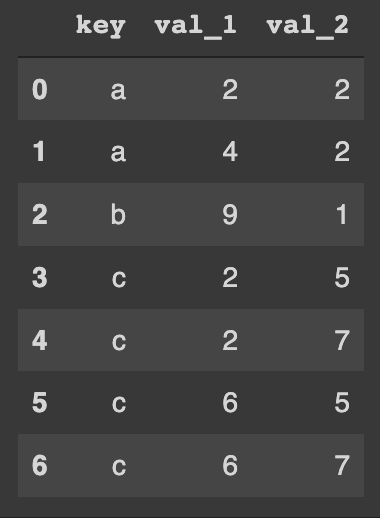
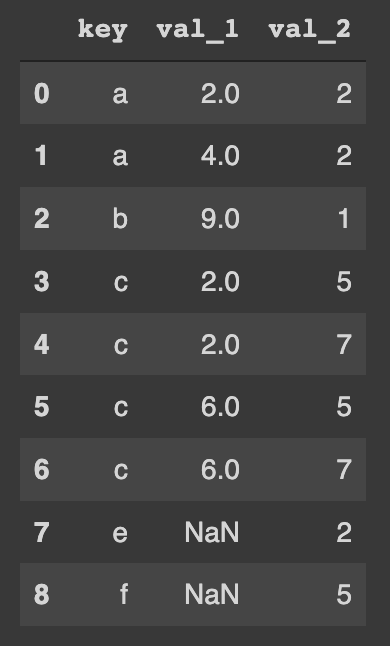
Then let's try to perform an outer join also on the "key" column:
pd.merge(df_1, df_2, how='outer', on='key')The resulted DataFrame is:
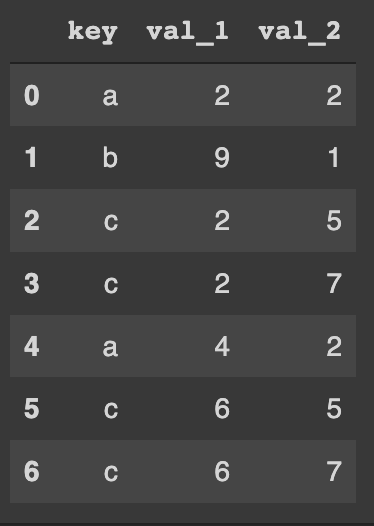
This is how to perform a left join on the "key" column:
pd.merge(df_1, df_2, how='left', on='key')The resulted DataFrame is:
Perform a right join on the "key" column:
pd.merge(df_1, df_2, how='right', on='key')The resulted DataFrame is:

Let's define another two dummy DataFrames with different column names:
df_3 = pd.DataFrame({
'key_3': ['a', 'b', 'c', 'c', 'd', 'e', 'e', 'f'],
'val_3': np.random.randint(10, size=8)
})
df_4 = pd.DataFrame({
'key_4': ['b', 'c', 'd', 'd', 'e', 'g'],
'val_4': np.random.randint(10, size=6)
})
print(df_3)
print()
print(df_4)The two dummy DataFrames are:
key_3 val_3
0 a 2
1 b 1
2 c 2
3 c 9
4 d 0
5 e 6
6 e 3
7 f 0
key_4 val_4
0 b 8
1 c 6
2 d 1
3 d 3
4 e 6
5 g 9We can also specify different columns from the two DataFrames to join on:
pd.merge(df_3, df_4, how='inner', left_on='key_3', right_on='key_4')The resulted DataFrame is:

Define two new dummy DataFrames:
df_5 = pd.DataFrame({
'key': ['a', 'b', 'c', 'a', 'c'],
'val_5': np.random.randint(10, size=5),
'name': ['Terry', 'Michael', 'Nancy', 'Terry', 'James']
})
df_6 = pd.DataFrame({
'key': ['b', 'c', 'e', 'c', 'f', 'a'],
'val_6': np.random.randint(10, size=6),
'name': ['Jason', 'Kobe', 'Mars', 'Jordan', 'Kobe', 'Steve']
})
print(df_5)
print()
print(df_6)The two dummy DataFrames are:
key val_5 name
0 a 3 Terry
1 b 3 Michael
2 c 1 Nancy
3 a 7 Terry
4 c 6 James
key val_6 name
0 b 9 Jason
1 c 2 Kobe
2 e 0 Mars
3 c 1 Jordan
4 f 4 Kobe
5 a 8 SteveThe two DataFrames can also be joined on multiple columns:
pd.merge(df_5, df_6, on=['key', 'name'], how='outer')The resulted DataFrame is:
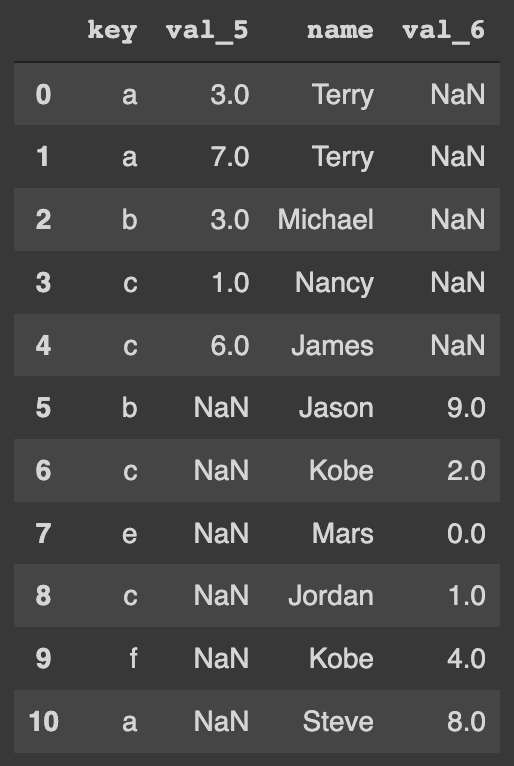
If we merge these two DataFrames on the "key" column:
pd.merge(df_5, df_6, on='key', how='outer')The resulted DataFrame is:
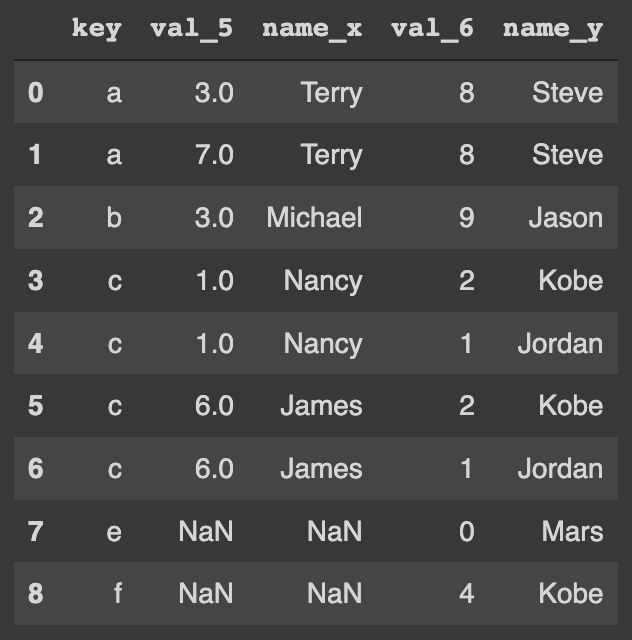
We can see how the columns with the same name from the two DataFrames are handled in this case. If you don't like this way, one can always define customized suffixes:
pd.merge(df_5, df_6, on='key', suffixes=['_1', '_2'], how='inner')The resulted DataFrame is:

Besides merging on the same column(s), indices of the DataFrames can also be used for merging. Let's define two new dummy DataFrames:
df_7 = pd.DataFrame({
'letter': ['a', 'b', 'c', 'b', 'e'],
'num': range(5)
})
df_8 = pd.DataFrame({
'value': range(4)
}, index=['a', 'c', 'e', 'f'])
print(df_7)
print()
print(df_8)The dummy DataFrames are:
letter num
0 a 0
1 b 1
2 c 2
3 b 3
4 e 4
value
a 0
c 1
e 2
f 3This is how to perform an inner join of these two DataFrames on the "letter" column of the first one and the index of the second one:
pd.merge(df_7, df_8, how='inner', left_on="letter", right_index=True)The resulted DataFrame is:

Another two new dummy DataFrames are defined as follows:
df_9 = pd.DataFrame(
[[1, 2], [3, 4], [5, 6]],
index=['a', 'c', 'd'],
columns=['Kobe', 'James']
)
df_10 = pd.DataFrame(
[[4, 2], [5, 8], [1, 6], [2, 7]],
index=['a', 'b', 'd', 'f'],
columns=['Steve', 'Michael']
)
print(df_9)
print()
print(df_10)Which are:
Kobe James
a 1 2
c 3 4
d 5 6
Steve Michael
a 4 2
b 5 8
d 1 6
f 2 7Let's merge them both on the indices:
pd.merge(df_9, df_10, left_index=True, right_index=True, how='outer')The resulted DataFrame is:
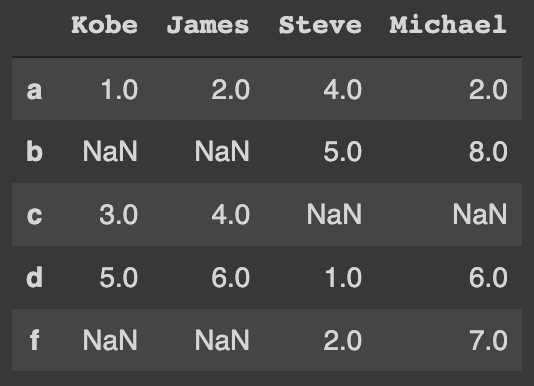
When joining DataFrames on indices, the .join method can also be used:
df_9.join(df_10, how='inner')The resulted DataFrame is:
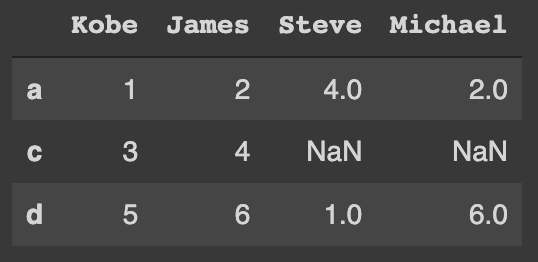
To perform an outer join:
df_9.join(df_10, how='outer')The resulted DataFrame is:
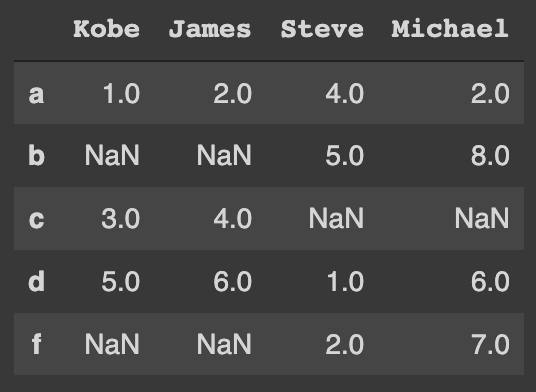
If we define an extra dummy DataFrame as:
df_11 = pd.DataFrame(
[[1, 5], [8, 4], [9, 6]],
index=['d', 'a', 'c'],
columns=['Nancy', 'Mars']
)
df_11Which is:
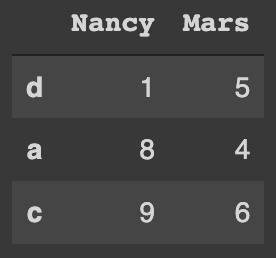
Then this is how we inner join the three DataFrames together:
df_9.join([df_10, df_11], how='inner')The resulted DataFrame is:

Combining Series/DataFrames Using pd.concat
The pd.concat method can also be used to combine Pandas Series or DataFrames. Let's first take a look on how it works on Series. Define three dummy Series as follows:
series_1 = pd.Series([0, 1], index=['a', 'b'])
series_2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
series_3 = pd.Series([5, 6], index=['f', 'g'])
print(series_1)
print()
print(series_2)
print()
print(series_3)The Series are:
a 0
b 1
dtype: int64
c 2
d 3
e 4
dtype: int64
f 5
g 6
dtype: int64This is how they can be concatenated using index as the axis:
pd.concat([series_1, series_2, series_3], axis=0)The resulted Series is:
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64They can also be concatenated using column as the axis:
pd.concat([series_1, series_2, series_3], axis=1)The resulted DataFrame is:
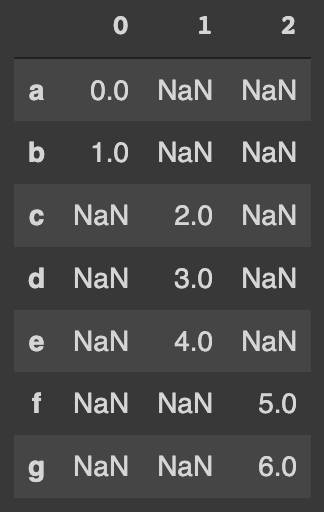
Note that the default behavior of pd.concat is outer join for axis=1. Define an extra dummy Series:
series_4 = pd.Series([7, 8, 9], index=['a', 'f', 'b'])
series_4Which is:
a 7
f 8
b 9
dtype: int64We can also perform an inner join for axis=1:
pd.concat([series_1, series_4], axis=1, join='inner')The resulted DataFrame is:

Extra hierarchies can also be defined using pd.concat with axis=0:
concated_series = pd.concat([series_1, series_2, series_4], keys=['one', 'two', 'three'], axis=0)
concated_seriesThe resulted Series is:
one a 0
b 1
two c 2
d 3
e 4
three a 7
f 8
b 9
dtype: int64The original Series can be retrieved through keys:
concated_series['one']Which yields:
a 0
b 1
dtype: int64The keys become columns using pd.concat with axis=1:
concated_df = pd.concat([series_1, series_2, series_4], keys=['one', 'two', 'three'], axis=1)
concated_dfThe resulted DataFrame is:
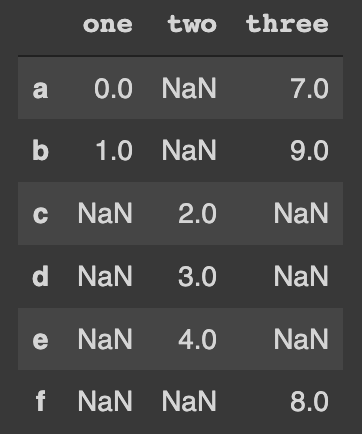
Now define two new dummy DataFrames with the same indices:
df_12 = pd.DataFrame(
[[1, 2], [3, 4], [5, 6]],
columns=['A', 'B']
)
df_13 = pd.DataFrame(
[[7, 8], [9, 10], [11, 12]],
columns=['A', 'B']
)
print(df_12)
print()
print(df_13)If we concatenate them along axis=0:
pd.concat([df_12, df_13], axis=0)The resulted DataFrame is:

It is seen that there are duplicates in the indices of the concatenated DataFrame, which is not the desired behavior. This issue can be fixed as follows:
pd.concat([df_12, df_13], ignore_index=True)The resulted DataFrame is:

Define another dummy DataFrame as follows:
df_14 = pd.DataFrame(
[[7, 9], [8, 10], [15, 20]],
columns=['C', 'D']
)
df_14Which is:

This is how DataFrames with the same indices can be concatenated along axis=1:
pd.concat([df_12, df_14], axis=1)The resulted DataFrame is:

It is also possible to add extra hierarchies. To demonstrate this, define two new dummy DataFrames:
df_15 = pd.DataFrame(
np.arange(6).reshape(3, 2),
index=['a', 'c', 'b'],
columns=['one', 'two']
)
df_16 = pd.DataFrame(
10 + np.arange(4).reshape(2,2),
index=['a', 'c'],
columns=['three', 'four']
)
print(df_15)
print()
print(df_16)Which are:
one two
a 0 1
c 2 3
b 4 5
three four
a 10 11
c 12 13The extra hierarchies can be added as follows:
pd.concat([df_15, df_16], axis=1, keys=['s1', 's2'])The resulted DataFrame is:
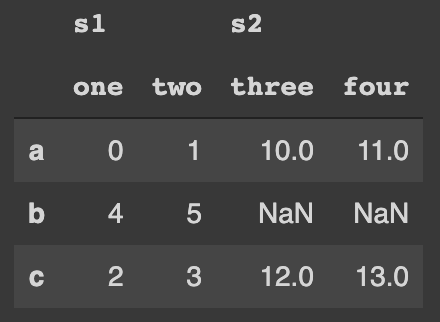
Conclusions
In this article, we mainly went through how to combine Pandas Series/DataFrames using the built-in pd.merge and pd.concat methods. Hope you enjoy it! More skills about Pandas will be covered in the future episodes. Stay tuned!
Get in Touch
Thank you for reading! Please let us know if you like this series or if you have critiques. If this series was helpful to you, please follow us and share this series to your friends.
If you or your company needs any help on projects related to drilling automation and optimization, AI, and data science, please get in touch with us Nvicta AI. We are here to help. Cheers!



Comments