Data Science in Drilling - Episode 17
- Zeyu Yan

- Aug 9, 2022
- 3 min read
Can We Use Python’ Async IO in AWS Lambda Function?
written by Zeyu Yan, Ph.D., Head of Data Science from Nvicta AI
Data Science in Drilling is a multi-episode series written by the technical team members in Nvicta AI. Nvicta AI is a startup company who helps drilling service companies increase their value offering by providing them with advanced AI and automation technologies and services. The goal of this Data Science in Drilling series is to provide both data engineers and drilling engineers an insight of the state-of-art techniques combining both drilling engineering and data science.
This is an exciting episode about both AWS Lambda and Python’s Async IO. Enjoy! :)

Enjoying great knowledge is just like enjoying delicious Japanese BBQ.
Introduction
We have already covered advanced usages of both AWS Lambda function and Python’s Async IO library in the previous episodes. However, there is still one question left to be answered. Most of the examples online about AWS Lambda function are all in a synchronous pattern. It is quite reasonable for us to think about using Python’s Async IO library to further improve the efficiency of our Lambda functions. But can the Async IO library actually be used in AWS Lambda functions?
Fortunately, the answer is yes! We will cover how to use Python’s Async IO library in AWS Lambda functions in detail in this blog post.
Async IO in AWS Lambda
First, let’s create a new AWS Lambda function named asyncTest. We will author it from scratch with an environment of Python 3.8, which supports the latest syntax of the Async IO library.
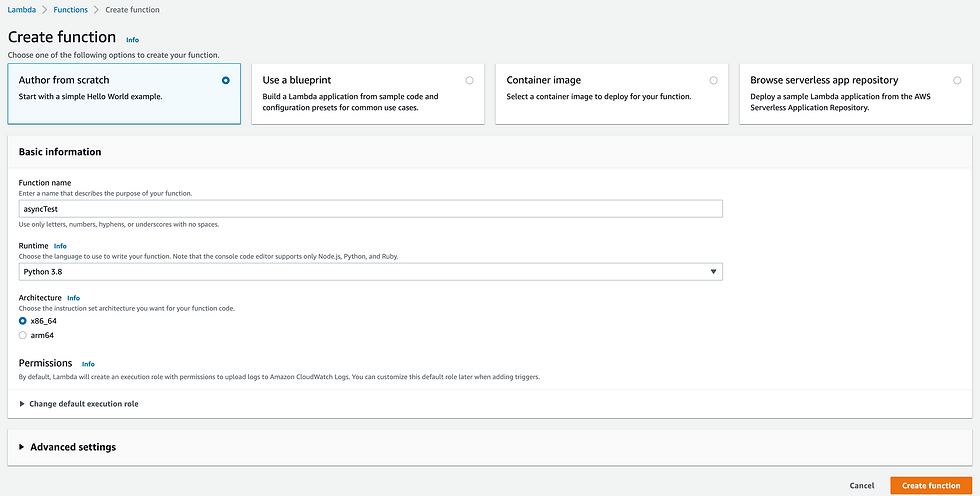
Then let’s author our Lambda function. The Lambda function is as follows:
import asyncio
import time
async def my_func(t):
await asyncio.sleep(t)
print(f'Slept for {t} seconds...')
async def main(t):
task_1 = asyncio.create_task(my_func(t + 1))
task_2 = asyncio.create_task(my_func(t))
await task_1
await task_2
print('All finished...')
def lambda_handler(event, context):
t = event.get('t', 0.5)
print(f't passed to Lambda function is {t}')
start = time.time()
asyncio.run(main(t))
end = time.time()
total_time_consumption = end - start
return {'total_time_consumption': total_time_consumption}What this Lambda function does is that it receives a parameter t as its input and run two async functions in parallel. We also added some print statements whose results can be retrieved from AWS CloudWatch. It is seen that our strategy is to define all the async functions outside the lambda_handler function and only use the asyncio.run method to start the event loop inside the lambda_handler function.
Now with our Lambda function defined, the next step is to test it to see if it works as expected. We can test the Lambda function directly from the AWS console, but this time we will write a Python script to test it instead.
Let’s install the necessary dependencies first. We will use the async version of the boto3 package in this test, as well as the dotenv package to manage the environment variables.
pip install aioboto3
pip install python-dotenvCreate a .env file to store the necessary credentials:
AWS_ACCESS_KEY_ID=YOUR_AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY=YOUR_AWS_SECRET_ACCESS_KEY
AWS_REGION=YOUR_AWS_REGIONNext, create a utils.py file to store some utility functions and variables:
from pathlib import Path
def get_project_root() -> Path:
return Path(__file__).parent
ENV_PATH = get_project_root().joinpath('.env')Finally, create a test.py file as our main test file with the following content:
import aioboto3
from dotenv import load_dotenv
import os
import json
import asyncio
from utils import ENV_PATH
load_dotenv(dotenv_path=ENV_PATH)
boto3_session = aioboto3.Session()
async def main():
async with boto3_session.client(
'lambda',
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),
region_name=os.getenv('AWS_REGION')
) as lambda_client:
response = await lambda_client.invoke(
FunctionName='asyncTest',
InvocationType="RequestResponse",
Payload=json.dumps({'t': 1})
)
if response['StatusCode'] == 200:
result = await response['Payload'].read()
result = json.loads(result)
print(f'result: {result}')
else:
print(response["ResponseMetadata"])
if __name__ == '__main__':
asyncio.run(main())result: {'total_time_consumption': 2.002145767211914}If we take a look at the logs from AWS CloudWatch:

The results are:

From the result returned from the Lambda function and the logs from the CloudWatch, it can be seen that the two async functions we defined in the Lambda function actually executed in parallel. This proved that the Async IO library worked as expected with AWS Lambda functions.
Conclusions
In this article, we covered how to combine Python's Async IO library with AWS Lambda functions to further improve Lambda functions' efficiencies. Hope you enjoy this article! More interesting contents will be covered in the future episodes. Stay tuned!
Get in Touch
Thank you for reading! Please let us know if you like this series or if you have critiques. If this series was helpful to you, please follow us and share this series to your friends.
If you or your company needs any help on projects related to drilling automation and optimization, AI, and data science, please get in touch with us Nvicta AI. We are here to help. Cheers!



Comentarios